

Проблема утечек данных является одной из наиболее острых в современном мире информационных технологий. Все чаще компании и их клиенты оказываются под угрозой в связи с возможными утечками конфиденциальной информации, что влечет за собой серьезные финансовые и репутационные риски.
Автор: Али Гаджиев, руководитель дирекции развития информационных систем Crosstech Solutions Group
Согласно исследованию Kaspersky Digital Footprint Intelligence, в 2023 г. объем опубликованных пользовательских данных вырос на 33% и составил 310 млн строк. Учитывая эти результаты, надежная защита данных стала приоритетной задачей для организаций любого масштаба.
В России действует ряд законов и стандартов, регламентирующих сбор, хранение и обработку персональных данных. Ключевыми являются Федеральный закон № 152-ФЗ «О персональных данных», ГОСТ Р 57580, PCI DSS и GDPR, которые устанавливают обязанности по обеспечению безопасности таких данных, а также требования к аудиту и оценке рисков в области информационной безопасности. Невыполнение этих требований может влечь за собой значительные административные штрафы для компаний, а также обесценивание их репутации перед клиентами и партнерами. Учитывая последние новости, связанные с ужесточением 152-ФЗ, а именно введение оборотных штрафов до 500 млн руб. и уголовной ответственности до 10 лет за утечки данных, соблюдение законодательства является сильным драйвером в обеспечении безопасности персональных данных пользователей и других конфиденциальных данных.
Конфиденциальные данные в большинстве своем хранятся в базах данных (БД). Это самый подходящий и распространенный способ хранения большого количества информации в структурированном удобном виде. При всех своих плюсах данный способ имеет множество уязвимостей, которые ведут к утечкам информации. Понимая это, компании – разработчики программного обеспечения активно инвестируют время и деньги для поиска способов противодействия данной проблеме. На данный момент на рынке существует более десятка классов решений, позволяющих защитить СУБД или данные в них, например:
DAM (Database Activity Monitoring) – решение, позволяющее мониторить действия пользователей в БД как в реальном времени, так и в ретроспективе;
UEBA (User and Entity Behavior Analytics) – решение для выявления аномального поведения пользователей, в частности при обращении к БД, с использованием технологий машинного обучения;
PAM (Privileged Access Management) – решение для контроля привилегированных пользователей с помощью единого портала и записей сессий;
DLP (Data Loss Prevention) – системы защиты от утечек конфиденциальной информации, следящие за периметром и анализирующие входящие и исходящие сообщения сотрудников.
Все эти решения помогают бороться с хищением информации из БД, зачастую являясь основным способом защиты производственных (продуктивных) баз данных. При этом на каждую продуктивную базу данных приходится в среднем 8–10 ее копий. Данные копии часто бывают необходимы различным пользователям как внутри, так и вне компании для выполнения своих рабочих обязанностей: разработчикам и тестировщикам в ходе реализации цифровых продуктов, аналитикам для проведения исследований и формирования отчетов по данным, подрядчикам и третьим лицам по самым разным причинам.
Рассмотрим пример. Компания-ритейлер хочет разработать решение для своих клиентов – онлайн-магазин. Для этих целей она нанимает подрядную организацию, которая и будет разрабатывать данное решение. Формируется ТЗ и запускается процесс разработки, в ходе которого будут выпускаться релизы и дорабатываться функционал. Но перед выпуском каждого релиза необходимо проводить функциональное и интеграционное тестирование, тестирование производительности, чтобы удостовериться, что разработанная система отвечает всем требованиям.
Для того чтобы данные тесты были максимально эффективны, занимали мало времени, а разработанная система после ее вывода в «прод» работала без ошибок, необходимо проводить тестирование на данных, максимально приближенных к реальным, а в идеале – на продуктивных БД. Однако подготавливать качественные данные вручную – крайне непростая задача, а тестирование на продуктивных базах сильно увеличивает риск утечки конфиденциальной информации. Вдобавок ко всему актуальной является проблема поиска информации в БД, так как пользователям приходится вручную анализировать все таблицы и выявлять, содержит ли та или иная таблица критичные данные.
Встает вопрос: как защитить непроизводственные среды? Можно распространять стандартные средства защиты информации на копии баз данных, но куда более эффективно будет заменить всю чувствительную информацию, которая в них хранится, на обезличенную, ведь разработчикам, тестировщикам или аналитикам нет необходимости иметь доступ к реальным данным для целей, описанных выше, достаточно будет иметь в наличии копию БД, которая по своей структуре ничем не отличается от продуктивной базы и наполнена данными, похожими на настоящие.
Процесс замены чувствительной информации на «ненастоящую» или обезличенную называется маскированием данных и позволяет уменьшить поверхность потенциальных атак злоумышленников, ведь в случае компрометации обезличенных копий БД практически отсутствуют финансовые или репутационные риски: оригинальных данных в этих базах нет. Для автоматизации этого процесса существуют системы класса Data Masking, которые становятся неотъемлемой частью работы компаний и позволяют эффективно контролировать доступ к конфиденциальной информации.
Одной из таких систем является Jay Data – российская платформа, специализирующаяся на поиске, классификации и маскировании конфиденциальной информации в базах данных. Это решение помогает компаниям обеспечить безопасность персональных данных, соблюдать требования законодательства (включая PCI DSS, GDPR, 152-ФЗ, ISO/IEC 27001:2022) и оптимизировать процессы подготовки тестовых данных.
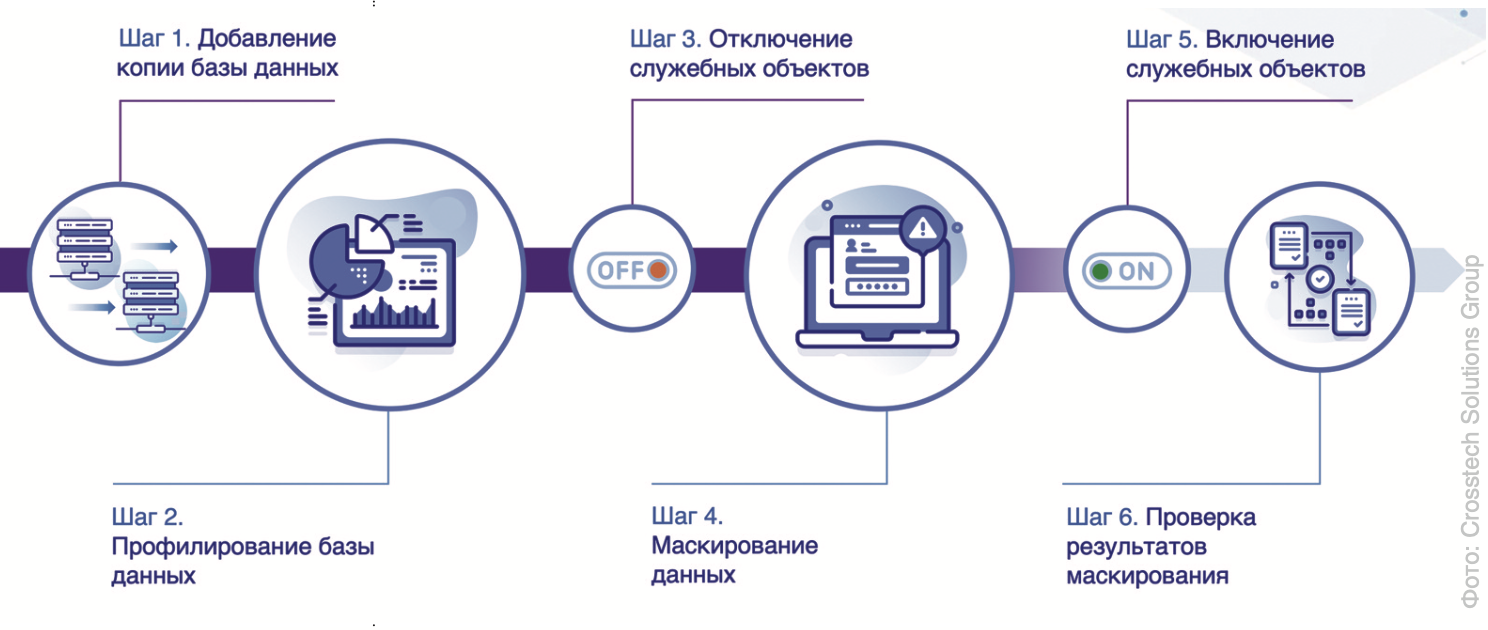
Процесс маскирования в Jay Data устроен следующим образом.
Подключение БД. Первым делом к системе подключаются копии БД, которые необходимо обезличить.
Профилирование. Далее необходимо определить, находится ли в данных БД чувствительная информация и в каких таблицах она располагается. Для этого в Jay Data реализован функционал автоматического поиска и классификации чувствительной информации, который называется профилированием.
Маскирование. На следующем шаге чувствительные данные заменяются на обезличенные, а прочие данные остаются в оригинальном виде. В ходе маскирования система также позволяет работать со служебными объектами и генерировать данные в соответствии с ограничениями уникальности, триггерами и пр.
Проверка результатов. Последним этапом система проверяет результаты маскирования и выдает пользователю базу данных, которую можно в безопасном виде передавать третьим лицам.
{kind=link}
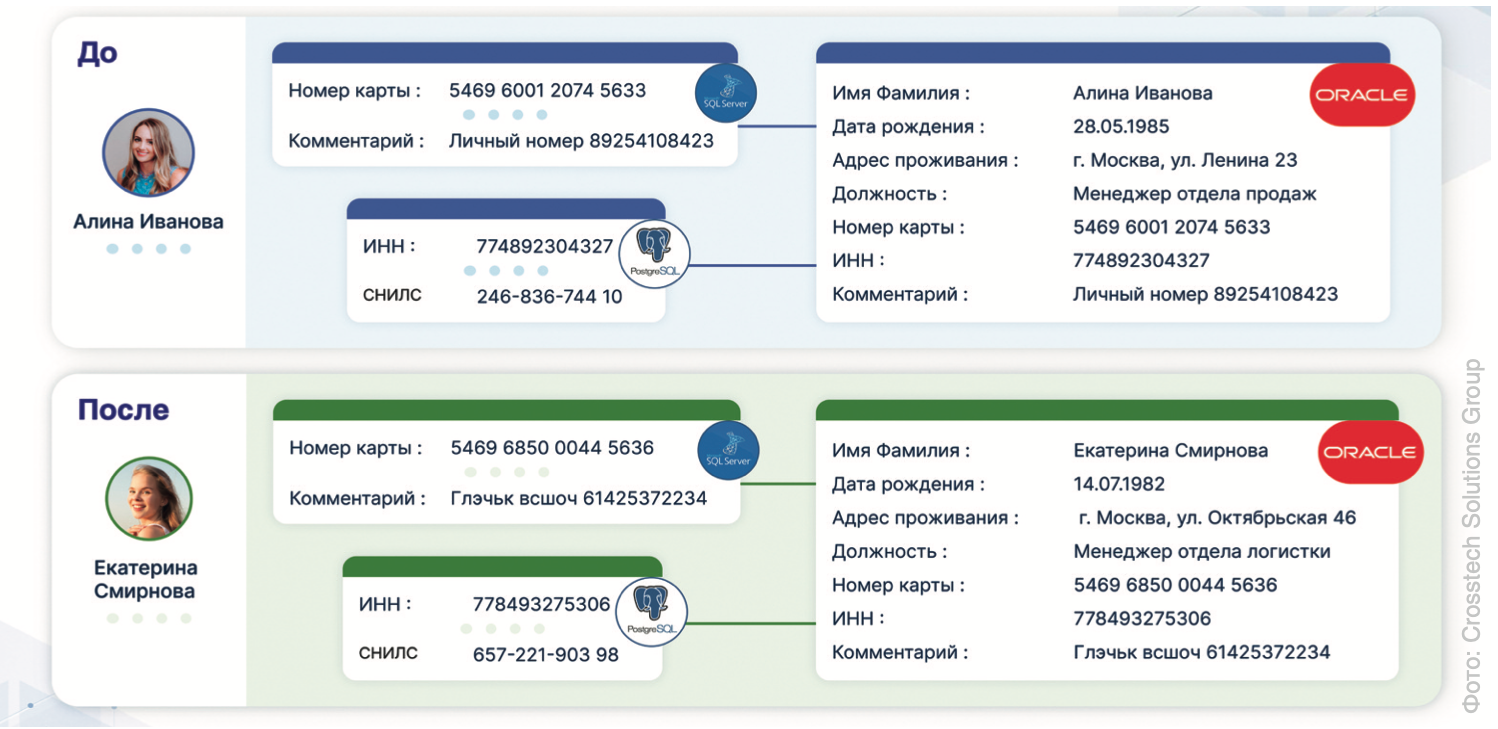
В Jay Data предусмотрено множество методов маскирования «из коробки» для реализации разных задач. Например, если необходимо просто «удалить» конфиденциальную информацию перед отправкой на сторону, то можно применить такие простые методы, как замена на константу, замена на null или замена N-символов на звездочку. А в случае наличия потребности в качественных данных, которые будут использоваться при тестировании разрабатываемых приложений, отлично подойдут такие методы, как замена по словарю (для маскирования имен, улиц, городов и пр.), посимвольная случайная замена (цифры заменяются на цифры, буквы на буквы), а также замена номеров карт, ИНН, СНИЛС и других документов, которые должны генерироваться с учетом различных алгоритмов (например, алгоритм Лу’на). То есть данные можно заменить таким образом, что конечный получатель даже не узнает, что они не оригинальные.
Примеры методов маскирования Jay Data
{kind=link}
В результате внедрения Jay Data компании получают значительные преимущества, такие как сокращение времени выхода разрабатываемых продуктов на рынок (Time-to-Market), снижение рисков утечек данных, безопасное использование конфиденциальных данных в различных сценариях и оптимизация тестирования. Учитывая постоянный рост объема хранимых данных (в том числе персональных данных клиентов), компаниям стоит ответственно подойти к вопросам обеспечения их безопасности и выбора решения, наиболее подходящего для данной цели.
ITSec_articles