
Проблема обеспечения непрерывности бизнеса является важнейшей для любой современной организации. Конечно же, существуют методы позволяющие подготовиться к возникновению нештатных ситуаций, поэтому при разработке стратегии управления непрерывностью бизнеса (Business Continuity Management или BCM) необходимо учесть риски остановки бизнес-процессов компании, а также разработать план действий, нацеленный на восстановление работоспособности после аварии.
Очевидно, что любой руководитель стремится минимизировать шанс возникновения неприятностей, и проактивно воздействовать на ситуацию, нежели бороться с последствиями этих неприятностей. В этой статье мы рассмотрим технические аспекты, позволяющие свести риски остановки бизнеса к минимуму еще на стадии проектирования центра обработки данных вашей компании.
Для того чтобы принять верное решение при планировании центра обработки данных вашей компании, необходимо определить какой максимальный промежуток времени вы можете позволить себе обходиться с неработающими сервисами, обеспечивающими бизнес информацией. Для некоторых компонентов вы можете позволить простой длительностью в сутки, который не принесет больших убытков, но другие компоненты могут за десятки минут принести серьезные потери. Типичным примером может служить процессинг банка. Такие системы являются “mission-critical” для компании и нуждаются в дополнительных средствах защиты. На сегодняшний день существует ряд решений обеспечивающих отказоустойчивость и даже катастрофоустойчивость системы. Эти решения отличаются технологической сложностью, требованиями к оборудованию и, конечно же, стоимостью. Рассмотрим возможные варианты позволяющие оградить бизнес от возможных неприятностей.
Простейшим решением является система высокой доступности, которая имеет достаточную избыточность для продолжения работы в случае одного из компонентов системы, таких как процессор, жесткий диск или сетевая карта. Если такой отказ происходит, система переносит рабочую нагрузку на резервные устройства или даже на другой узел. Типичная система высокой доступности, которая также известна как кластер высокой доступности, изображена на рис. 1.
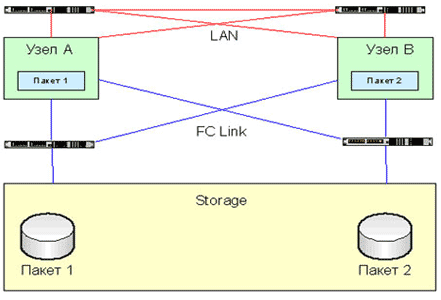
Рис. 1. Кластер высокой доступности
Но в некоторых случаях такая защита не сможет обеспечить достаточный уровень надежности. В случае полного краха площадки, на которой расположен ваш центр обработки данных для поддержания непрерывности бизнеса необходимо решение, обеспечивающее работу при множественных точках отказа. Поэтому далее в статье будут рассматриваться катастрофоустойчивые системы.
Катастрофоустойчивость – это возможность восстановить работоспособность приложений обеспечивающих непрерывность бизнеса в течение приемлемого периода времени. Часто полагают, что катастрофой являются пожар, потоп, землетрясение и другие природные или техногенные катаклизмы, на самом деле это не так. Катастрофой можно считать любое событие, ведущее к остановке сервиса, обеспечивающего непрерывность бизнеса, или потере данных.
Катастрофоустойчивая система представляет собой дальнейшее развитие систем высокой доступности. Основным различием является территориальное разнесение узлов кластера. В зависимости от расстояния между узлами, а также от технологий передачи и репликации данных, можно выделить 3 основных класса катастрофоустойчивых систем: распределенный кластер, метрокластер и континентальный кластер.
Распределенный кластер – это «рабочая лошадка» катастрофоустойчивых систем. Такое решение применяется в случае наличия двух площадок на близком расстоянии друг от друга, типичным случаем являются два соседних здания на одной территории. В случае применения распределенного кластера у вас будет два отдельных центра обработки данных, которые потребуют для соединения волоконнно-оптический канал (Fibre Channel). И именно это накладывает ограничение на расстояние между узлами. На сегодняшний день это может быть максимум 100 километров при использовании DWDM (Dense Wave Division Multiplexing) соединения. Распределенный кластер изображен на рис. 2.
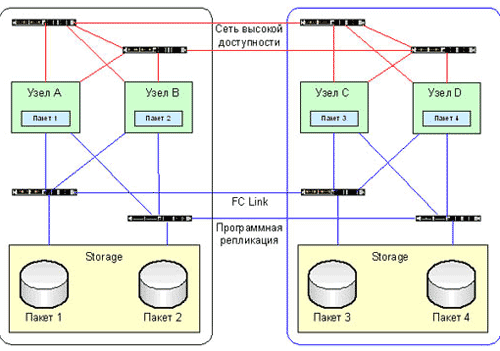
Рис. 2. Распределенный кластер.
Метрокластер, также известный как кластер масштаба города, отличается от распределенного лишь наличием третьей площадки, откуда осуществляется управление рабочими узлами, а так же технологией репликации данных. В случае распределенного кластера используется программная репликация, в метрокластере же используются аппаратные возможности дисковых массивов.
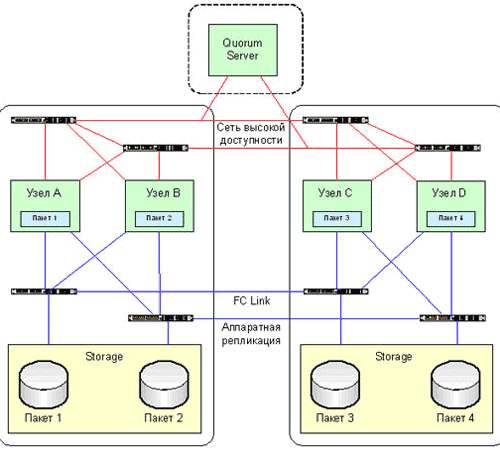
Рис. 3. Метрокластер.
Как распределенный, так и метрокластер ограничены в расстоянии между узлами только возможностями репликации данных и сетевых технологий.
Если ваши площадки разнесены больше, чем на 100 километров, то необходимо применять наиболее тяжелое решение – континентальный кластер. Основной отличительной особенностью такой системы является использование WAN, как транспортной сети репликации данных. Платой за такое расстояние между узлами будет необходимость использования широкополосных каналов, таких как E1 или E3, большая задержка при репликации и сложность при добавлении дополнительных узлов в кластер. Континентальные кластеры также могут служить для связи двух или нескольких решений меньшего масштаба.
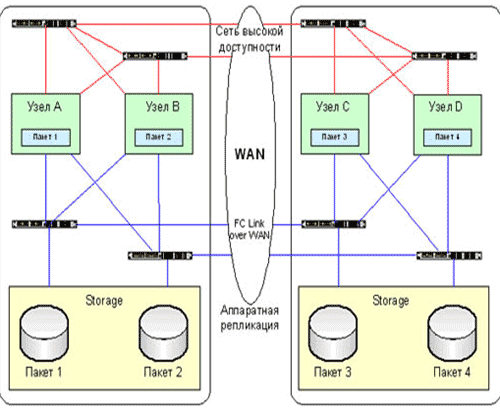
Рис. 4. Континентальный кластер.
Важной частью обеспечения катастрофоустойчивости является подготовка надежного помещения, которое позволит работать или корректно завершить работу системы даже в условиях, не предназначенных для функционирования аппаратного обеспечения.
Чтобы избежать проблем с эксплуатацией оборудования, для строящихся или реконструируемых помещений важно подготовить и выдать проектировщикам и строителям корректно сформулированное техническое задание. В нем должны быть описаны требования для всех компонентов информационной системы. Эти требования должны быть изучены всеми специалистами, имеющими отношение к строительной и инженерной инфраструктуре ИТ. Как правило, производители оборудования выдвигают требования к параметрам окружающей среды и электропитания, поэтому в случае проектирования крупного центра обработки данных необходимо учитывать количество и состав входящих в него компонентов будущей системы.
Основными факторами, влияющими на подготовку помещения для центра обработки данных являются:
- физическое пространство, занимаемое оборудованием;
- вес оборудования;
- потребляемая мощность;
- рассеиваемое тепло.
Собрав эти данные на этапе проектирования можно рассчитать необходимую прочность и размеры фальшполов и фальшпотолков, количество вводимых фаз электропитания, мощность систем бесперебойного питания и климатических установок, а также собственно площадь будущей серверной. Проектируя помещение всегда нужно учитывать необходимость свободного доступа и подвода сетевых коммуникаций к шкафам с оборудованием. Помимо всех вышеперечисленных требований, зависящих от состава будущего оборудования, есть рекомендации, которые требуются в любой серверной комнате:
- система автоматического пожаротушения и газоудаления;
- система аварийного освещения и средств оповещения;
- система видеонаблюдения и контроля доступа в серверную комнату;
- системы мониторинга параметров окружающей среды.
Если без выполнения критических требований невозможно организовать действительно отказоустойчивый центр обработки данных, то такие требования как антистатическое покрытие стен помещения, гидро- и виброизоляция помогут сделать серверную комнату еще более надежной.
Для обеспечения отказоустойчивости системы в целом, необходима исключительная надежность каждого из составляющих компонентов. Точкой отказа может стать собственно сам сервер, дисковый массив, источник питания, коммутатор и т.д. Наконец, еще одной точкой отказа является ошибка в программном обеспечении. Рассмотрим все эти кирпичики по отдельности.
Итак, современные серверы среднего и выше уровня предоставляют широкие возможности по резервированию и дублированию компонентов, поэтому при проектировании центра обработки данных нужно учесть, что необходимо дублировать все части серверов, которые поддерживают горячую замену. В нашем случае это жесткие диски, сетевые и адаптеры Fibre Channel или другие устройства ввода-вывода, блоки питания, помимо этого на ходу можно заменять вентиляторы системы охлаждения. Имея в горячем резерве эти компоненты можно поддерживать рабочее состояние системы даже в случае отказа части из них.
Другой точкой отказа системы может являться компоненты связанные с передачей данных. Никто не застрахован от экскаватора оборвавшего оптический кабель или отказа оборудования у провайдера. Можно рассматривать и простой случай – вышедший из строя коммутатор. Все эти события приводят к одним и тем же последствиям – сервис не предоставляется, а значит бизнес стоит. Чтобы исключить отказ в транспортной части кластера требуется подключать каждый интерфейс в отдельный сегмент сети с выделенными кабелями и коммутаторами. В случае отказа любого из компонентов соединение будет переведено на другой интерфейс незаметно для потребителей услуги. Если компоненты вашей системы достаточно сильно разбросаны (согласен) территориально и у вас нет собственных каналов передачи данных, лучше использовать каналы двух различных провайдеров, вероятность одновременного отказа обоих достаточно мала. Если же площадки расположены близко и вся инфраструктура контролируется компанией, то при проектировании ЦОД необходимо учесть необходимость прокладки двух кабелей желательно различными физическими путями.
Еще одним важнейшим компонентом является дисковая подсистема. Если вы работаете с отдельным дисковым массивом, подключенным в сеть хранения данных (Storage Area Network), все проблемы резервирования данных решаются на аппаратном уровне. Необходимо лишь обеспечить отказоустойчивое подключение в SAN серверов и для этого дублируются FC-коммутаторы и FC-адаптеры. Если вы по какой-либо причине используете подключение дисковой подсистемы с помощью общей SCSI шины, а также для встроенных дисков сервера необходимо использовать программную репликацию данных. Этим защищается и собственно операционная система на каждом из узлов и оперативные данные в случае отсутствия аппаратных RAID-контроллеров в дисковой подсистеме.
Подготовкой помещения и аппаратной части решается большая часть задачи построения катастрофоустойчивого центра обработки данных, но не вся. Поскольку приложения, используемые для обеспечения бизнеса, не всегда имеют встроенных средств для работы с отказоустойчивыми распределенными системами, необходимо использовать дополнительное программное обеспечение, которое будет управлять процессами на всех узлах системы и переключать задачи между ними. Совокупность программного и аппаратного обеспечения образует кластер высокой доступности. Каждый производитель систем для среднего и крупного бизнеса предоставляет свое программное обеспечения для реализации кластеров. Это MC/ServiceGuard от HP или Sun Cluster от Sun Microsystems, помимо этого существуют решения и от сторонних производителей, такие как Veritas Cluster и, конечно же, Microsoft Cluster. Каждый из этих продуктов работает на определенной платформе, но все они решают одни и те же задачи – управление программными продуктами на распределенной системе. Важно заметить, что кластер высокой доступности не всегда предоставляет возможности распределения нагрузки между узлами в случае функционирования системы в штатном режиме.
Итак, выше были описаны различные варианты отказоустойчивых и катастрофоустойчивых систем. Как выбрать наиболее подходящий для вашего бизнеса? Для решения этой проблемы необходимо учесть ряд критериев:
- От каких сервисов, предоставляемых ИТ службой компании, зависит непрерывность бизнеса?
- Какие убытки принесет отсутствие услуги в течение некоторого промежутка времени?
- Какова величина внешних рисков?
- Какой бюджет планируется на построение отказоустойчивого центра обработки данных?
Ответив на эти вопросы, вы сможете оценить размер средств, которые предстоит потратить на обеспечение непрерывности бизнеса. Каждый следующий шаг, обеспечивающий большую избыточность, увеличивает стоимость системы. Наконец наступает очередной шаг, когда затраты на отказоустойчивость превышают убытки от предполагаемых катастроф. Задача руководителя найти такую точку, которая соответствует минимальным затратам при максимально эффективной защите от возможных рисков.
Николай Савин, Андрей Семенчук
Директор информационной службы, № 12, декабрь 2004